JS: Arrays
Theory: Big O
When it comes to algorithms, it is impossible not to mention the concept of algorithm complexity (denoted as Big O). It gives an understanding of how effective an algorithm is.
As you no doubt remember, there are lots and lots of sorting algorithms. They all perform the same task, but they all work differently. In computer science, algorithms are often compared to each other based on their algorithmic complexity. This complexity is estimated by the number of operations an algorithm performs to achieve its goal. For example, different sorting methods require different numbers of passes through the array before the array is completely sorted. We know that the specific number of operations depends on the input data. For example, if the array is already sorted, then the number of operations will be minimal (but there are still going to be operations because the algorithm needs to make sure that the array is sorted).
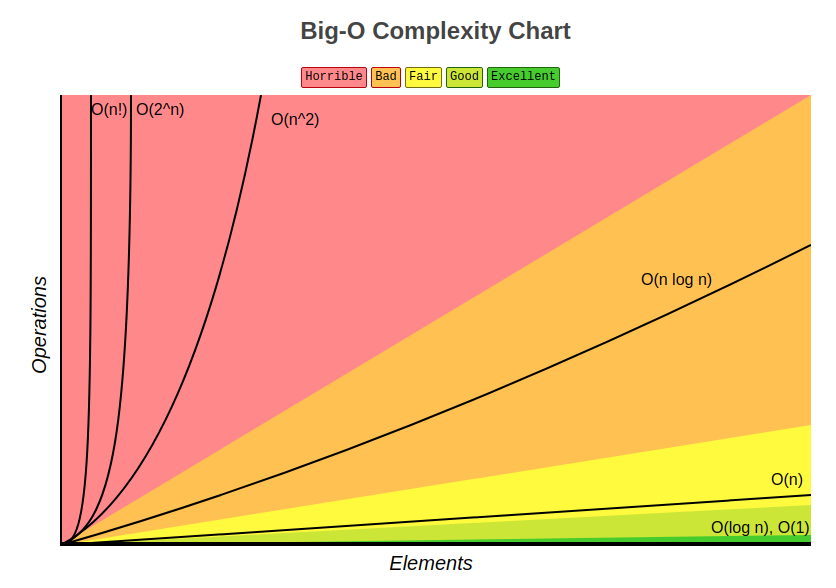
Big O notation was simply invented to describe algorithmic complexity. It's designed to show how much the number of operations will increase when the amount of data increases.
Here are some examples of how complexity is noted: O(1), O(n), O(nlog(n)).
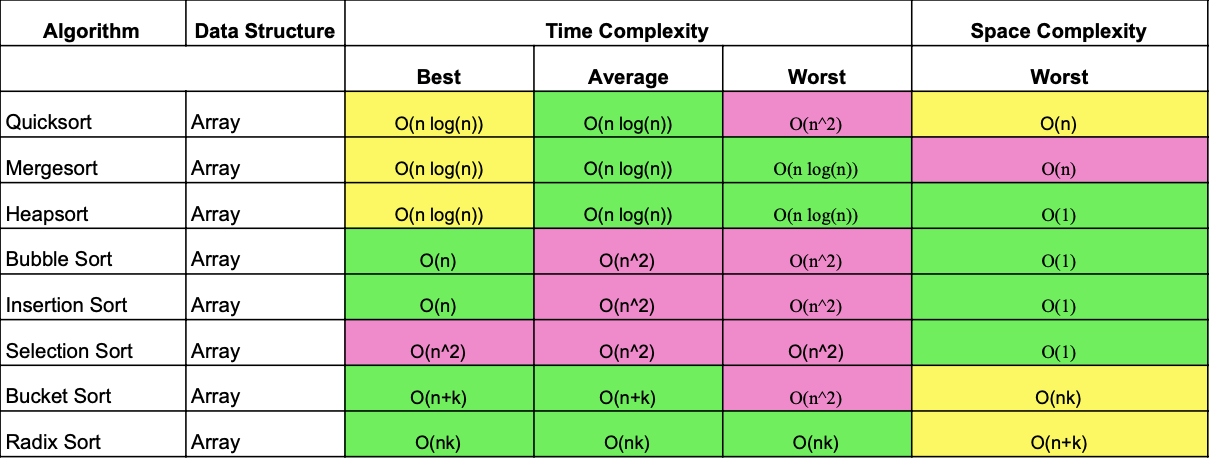
O(1) describes a constant complexity. This is the complexity of the operation of accessing an array element by index. The complexity (in the algorithmic sense) of accessing an element does not depend on the size of the array and is a constant value. But a function that prints all the elements of an array passed through, using the usual brute force, has a complexity of O(n) (linear complexity). I.e., the number of operations performed, in the worst case, will be equal to the number of elements in the array. This is the number represented by n in parentheses.
What is the worst-case scenario? Depending on what state the initial array is in, the number of operations will be different even if the array is the same size. To make it easier to understand, let's use a Rubik's Cube as an analogy. The number of operations (turns/twists etc.) that need to be done to get the Rubik's Cube in the right position depends on what position its faces are in before the assembly. In some cases, little action will be needed, in others you'll need a lot. And the worst-case scenario is when the maximum number of movements is needed. Algorithmic complexity is always estimated by the worst-case scenario for the chosen algorithm.
Another example is nested loops. Recall how the intersection search in unsorted arrays works. For each element in one array, each element in the other array is checked (either using a loop or with the includes() method. includes()'s complexity is O(n) because in the worst case it looks through the whole array). If we assume that the size of both arrays is the same and equal to n, then the search for intersections has quadratic complexity or O(n^2) (n squared).
There are both very effective and completely ineffective algorithms. The speed of such algorithms drops at a catastrophic rate, even with just a small number of elements. Often faster algorithms are faster not because they are better, but because they consume more memory or have the ability to run in parallel (and if they do, they run extremely efficiently). Like everything in engineering, efficiency is a trade-off. By winning in one place, we have to lose somewhere else.
Big O is largely a theoretical assessment, in practice things may be different. The actual execution time depends on many factors including processor architecture, operating system, programming language, memory access (sequential or arbitrary), and dozens of other things.
The question of code efficiency is quite dangerous. Since many people start learning to program with algorithms (especially at university), they begin to think that efficiency is the most important thing. Code must be fast.
This attitude to the code is much more likely to cause problems than fix them. It's important to understand that efficiency is the enemy of understandability. Such code is always more complicated, more error-prone, harder to modify, and takes longer to write. More importantly, real efficiency is rarely a pressing matter, and often isn't necessary at all. Usually, it's not slow code, but rather things such as database queries or the network that act as a bottleneck. But even if code is running slowly, it's likely that the exact piece you're trying to optimize is only called once during the program's life and doesn't affect anything because it's running with a small amount of memory. Meanwhile, there's another piece being called thousands of times, which causes a genuine slowdown.
Programmers spend a huge amount of time thinking and worrying about non-critical parts of the code and trying to optimize them, which has an extremely negative impact on subsequent debugging and support. We should forget about optimization, say about 97% of the time. Premature optimization is the root of all evil. Conversely, we must give our full attention to the remaining 3%. - Donald Knuth
Before you try to optimize any, be sure to read this little online book, which does a great job of explaining the essence of all optimizations.

