Git fundamentals
Theory: Index
An index in git is a special intermediate area that stores changes to files on the way from the working directory to the repository. When a commit is made, only the changes from the index are added to the repository.
The notion of an index in git did not appear by accident. Even when a developer is working on one task, along the way they'll stumble upon different parts of the code that are either poorly designed, contain errors, or need to be corrected to meet some new requirements. And in most situations, it's perfectly normal to fix these issues, it's what everyone does. As a result, there are many different fixes in the working directory, some of which are partly related to the task at hand, and some of which contain multiple fixes not directly related to the main changes. What's the problem here?
If you make exactly one commit that includes both the main task and additional fixes, there'll be a few unpleasant side effects. First of all, it's harder to look at the history. The commit starts to contain completely unrelated changes, which can be distracting when reviewing someone else's code.
Secondly, and probably even more importantly, rolling back a commit for whatever reason will roll back edits you'll have to make again.
This is where the index helps. It allows you to worry less about how a commit will be generated.
The standard way to work with an index is to add or change files and then commit:
If we're talking about one or two files that need to be committed right now, we can make it easier. The git commit command takes file path arguments as its input. It automatically adds these files to the index and then adds them to the commit. This approach works only with files that are already being tracked.
Sometimes it's the other way around - we've fixed lots of files and want to add them all to the commit at once. In this case, use a dot:
The command above is very dangerous. It makes it extremely easy to commit a lot of unnecessary stuff, especially if you don't remember to check git diff --staged before committing.
And an especially intimidating, but useful command is a commit that adds everything to the index simultaneously:
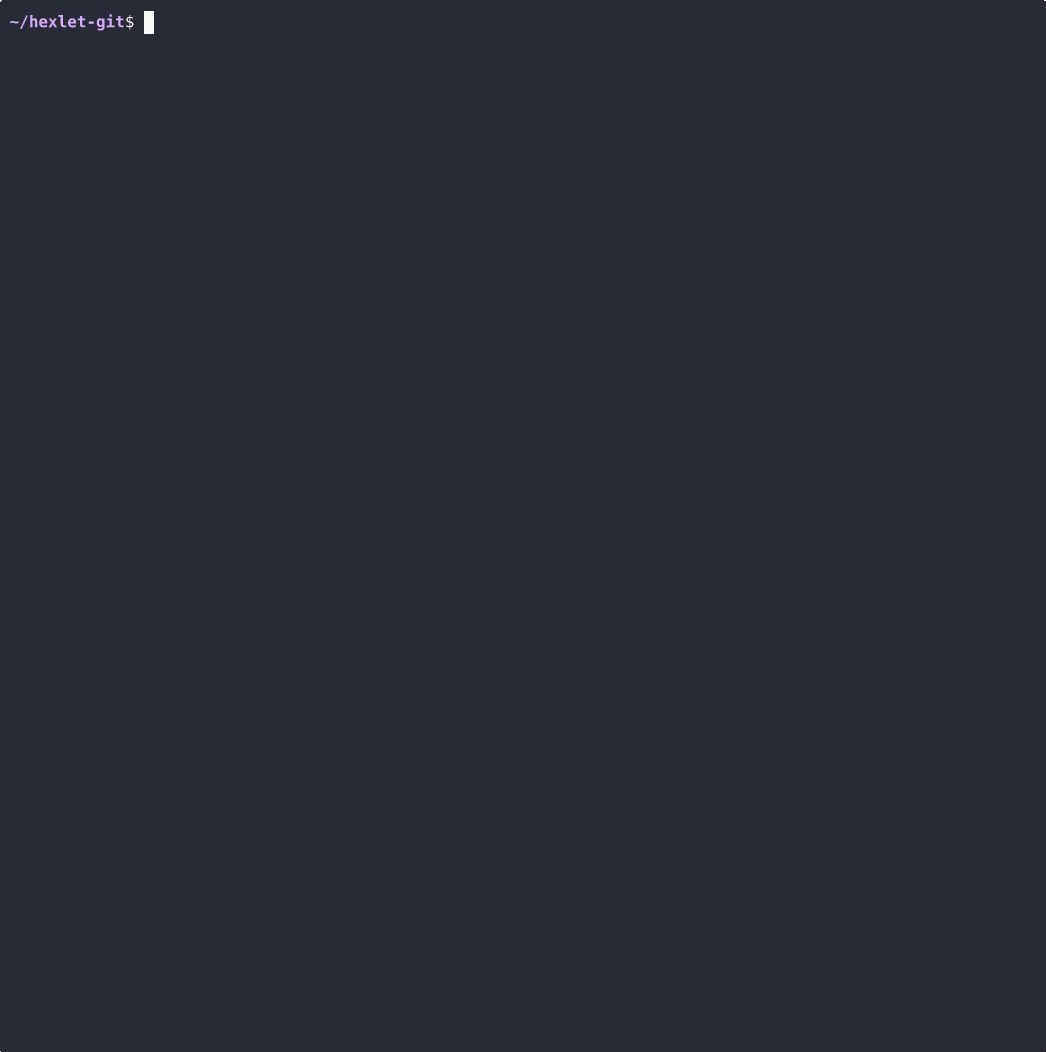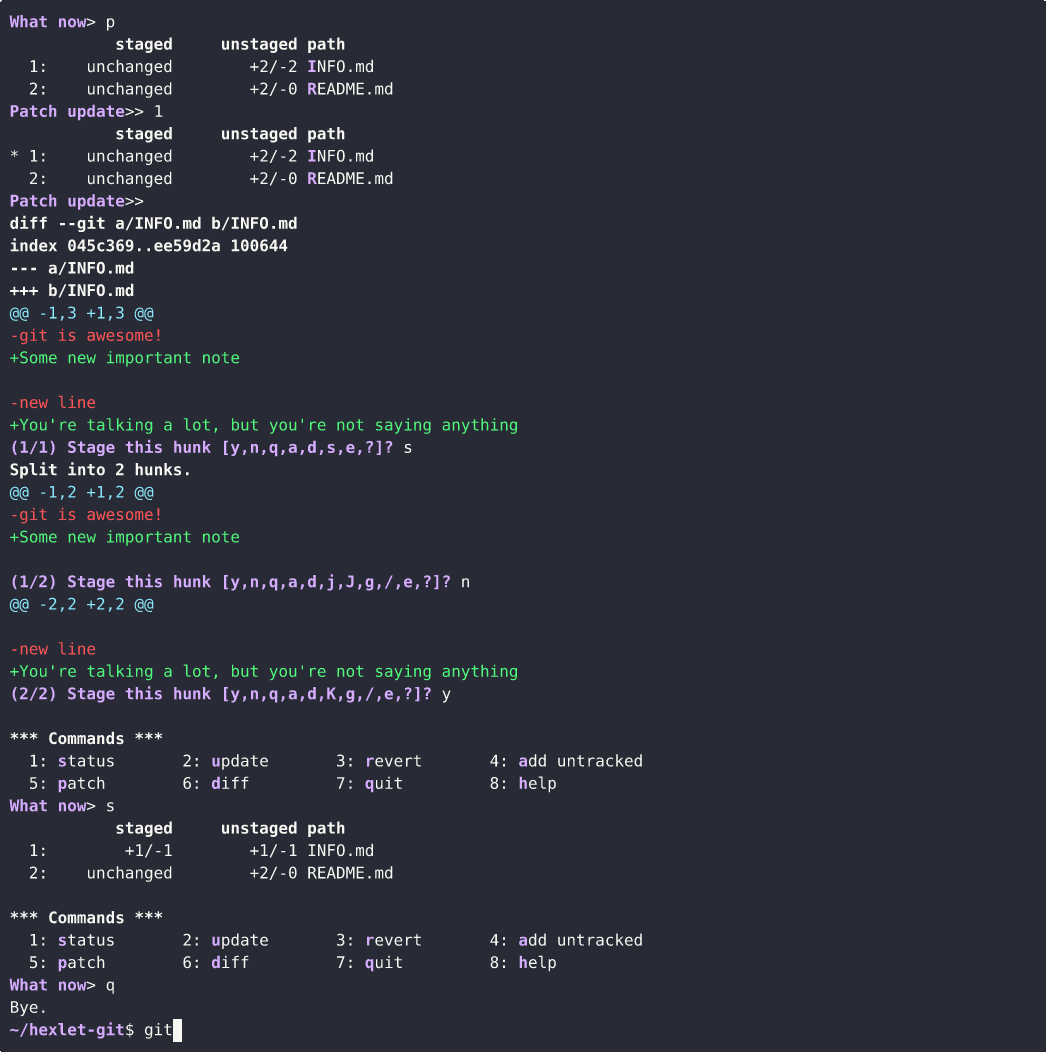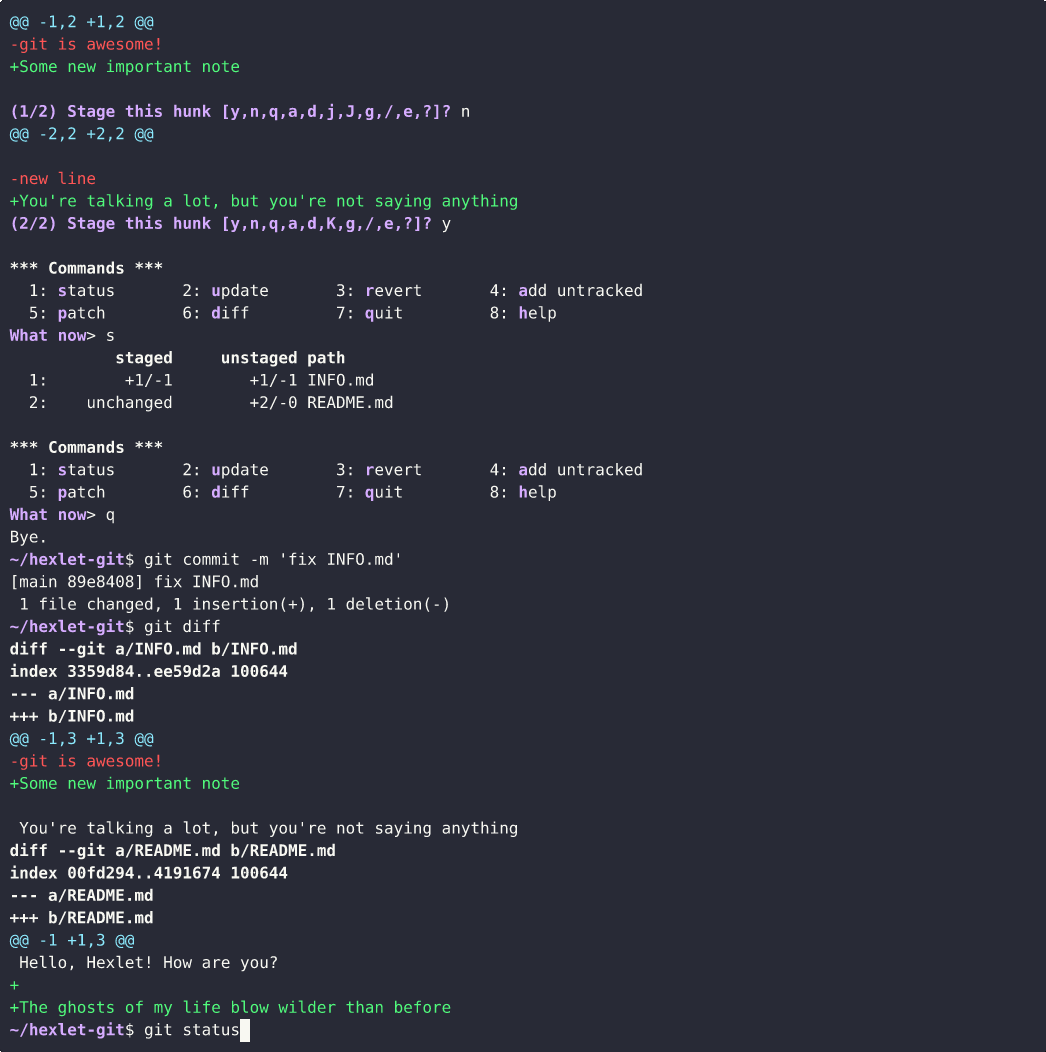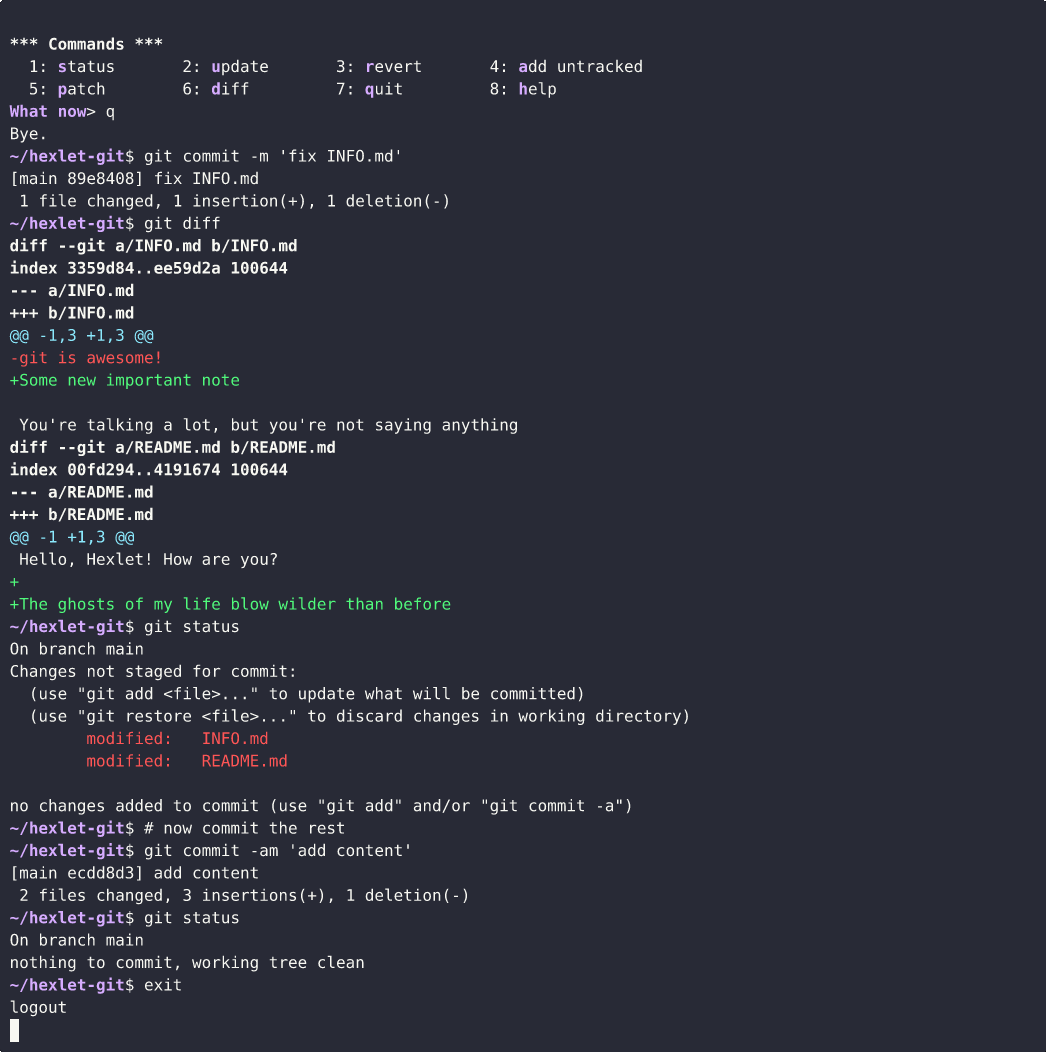
On the other hand, it's not uncommon for various changes to be made in the same files. In other words, the changes in these files should normally be in different commits. And even that can be done with git. The most suitable command for this is git add -i, which shows the changed parts of files and asks what to do with them. With this command, you can very precisely choose what should go into the commit and what shouldn't. Using it usually shows a good level of mastery of git.